
1st
machine learning
1. welcome to machine Learning
2. what can machine Learning do
2st
1. Define: what is machine learning?
2. Machine Learning algorithms
==2.1 Supervised learning (监督学习)== used most in real-world application
input to output label
x to y
learns from being given "right answers"
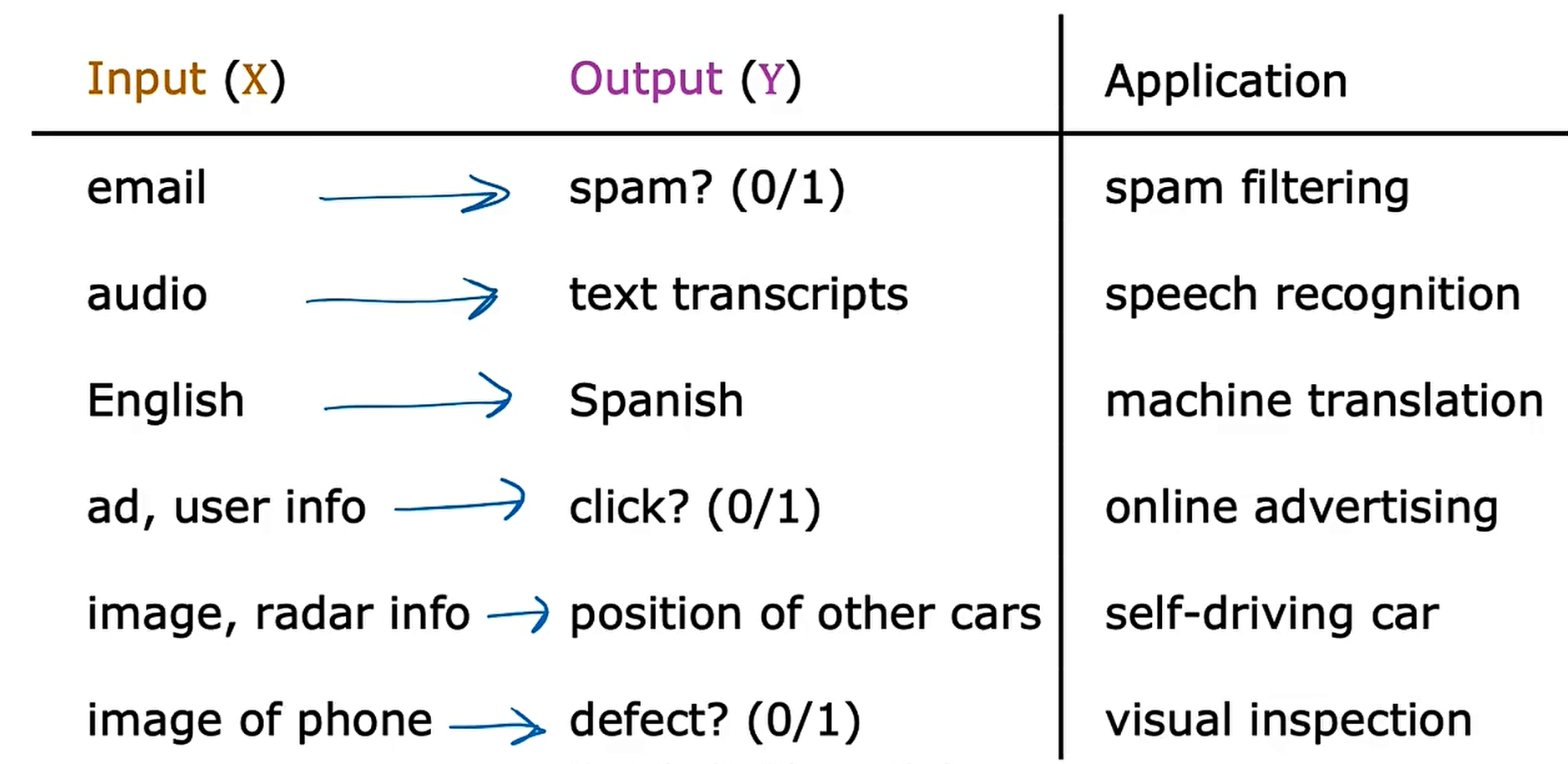
Regression: House price prediction ——回归问题
Predict a number infinitely many possible outputs.
Classification: Breast cancer detection —— 分类问题 class == category
Predict categories.
small number of possible outputs.
==2.2 Unsupervised learning==(无监督学习)
Find something interesting in unlabeled data.
Data only comes with inputs x, but not output labels y.
Algorithm has to find structure in the data.
Clustering(集群/群集/簇): Google news / Grouping customers
Group similar data points together.
Anomaly detection(异常检测):
Find unusual data points.
Dimensionality reduction(降维):
Compress data using fewer numbers.

3st
==Linear Regression Model==: 线性回归模型
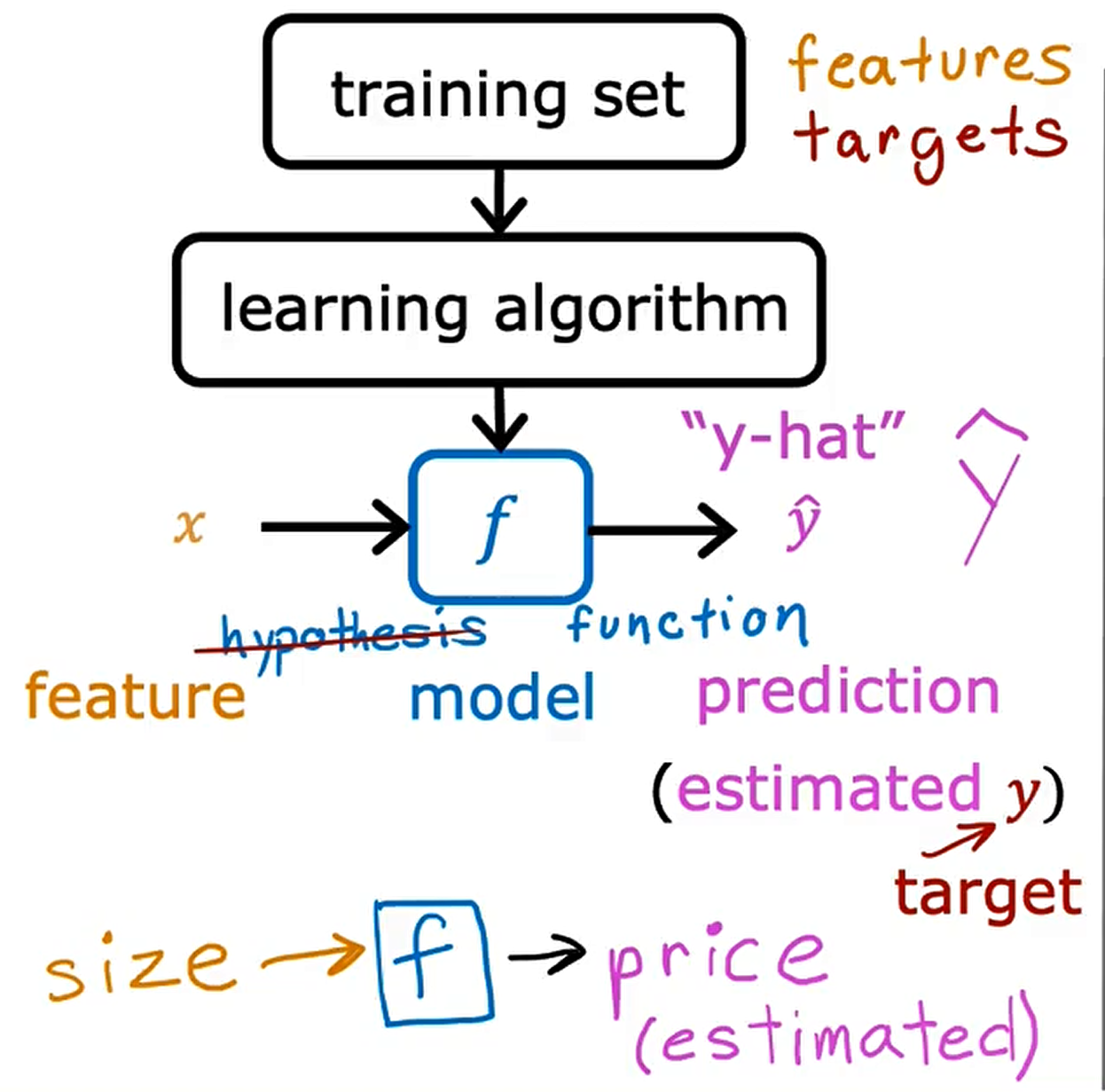
Terminology
Training set
Notation:
x = "input" variable
feature
y = "output" variable
"target" variable
m = number of training examples.
(x,y) = single training example.
$(x^{i},y^{i}) = i^{th}$ training example.
$\hat{y}$ is "y-hat" estimated y
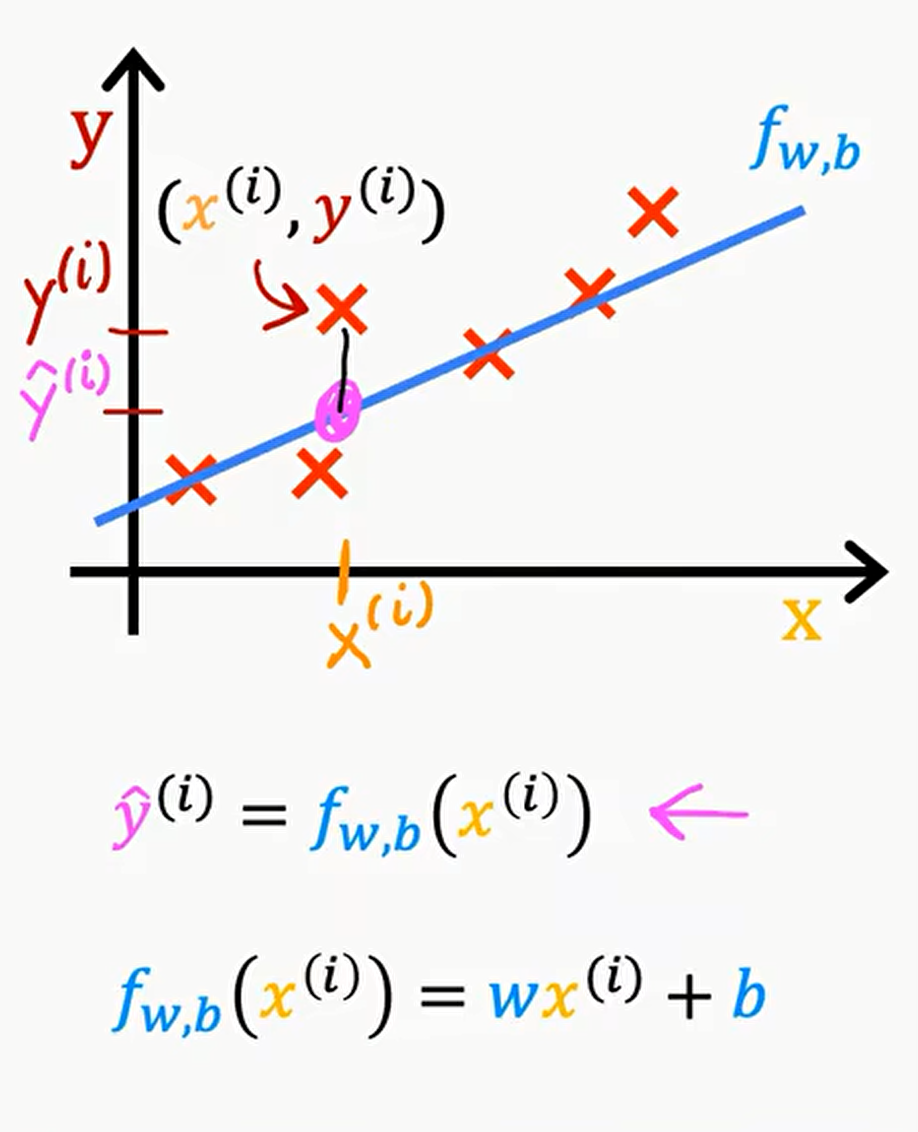
Linear regression with one variable. (单变量线性回归)
Univariate linear regression.
Cost Function 代价函数 or 成本函数
Squared error cost function 平方误差成本函数/代价函数
Model: $f_{w,b}(x) = wx + b$
w,b : parameters (系数/权重)
y-intercept:截距
slope:斜率
($\hat{y}$ - y) is be called error(误差)
$J_{w,b}=\frac{1}{2m}\sum_{i=1}^m(\hat{y}^{(i)} - y^{(i)})^2$ (m = number of training examples)
$J_{w,b}=\frac{1}{2m}\sum_{i=1}^m(f_{w,b}(x^{i}) - y^{(i)})^2$
Find w,b:
$\hat{y}$ is close to $y^{(i)}$ for all $(x^{(i)},y^{(i)})$
Conclusion
model:
$f_{w,b}(x) = wx + b$
parameters:
$w,b$
cost function:
$J_{w,b}=\frac{1}{2m}\sum_{i=1}^m(f_{w,b}(x^{i}) - y^{(i)})^2$
goal:
$\mathop{minimize} \limits_{w,b} J(w,b)$
Simplified
$f_{w}(x) = wx$ (if b = 0)
$J_{w}=\frac{1}{2m}\sum_{i=1}^m(f_{w}(x^{(i)}) - y^{(i)})^2$
$\mathop{minimize} \limits_{w} J(w)$
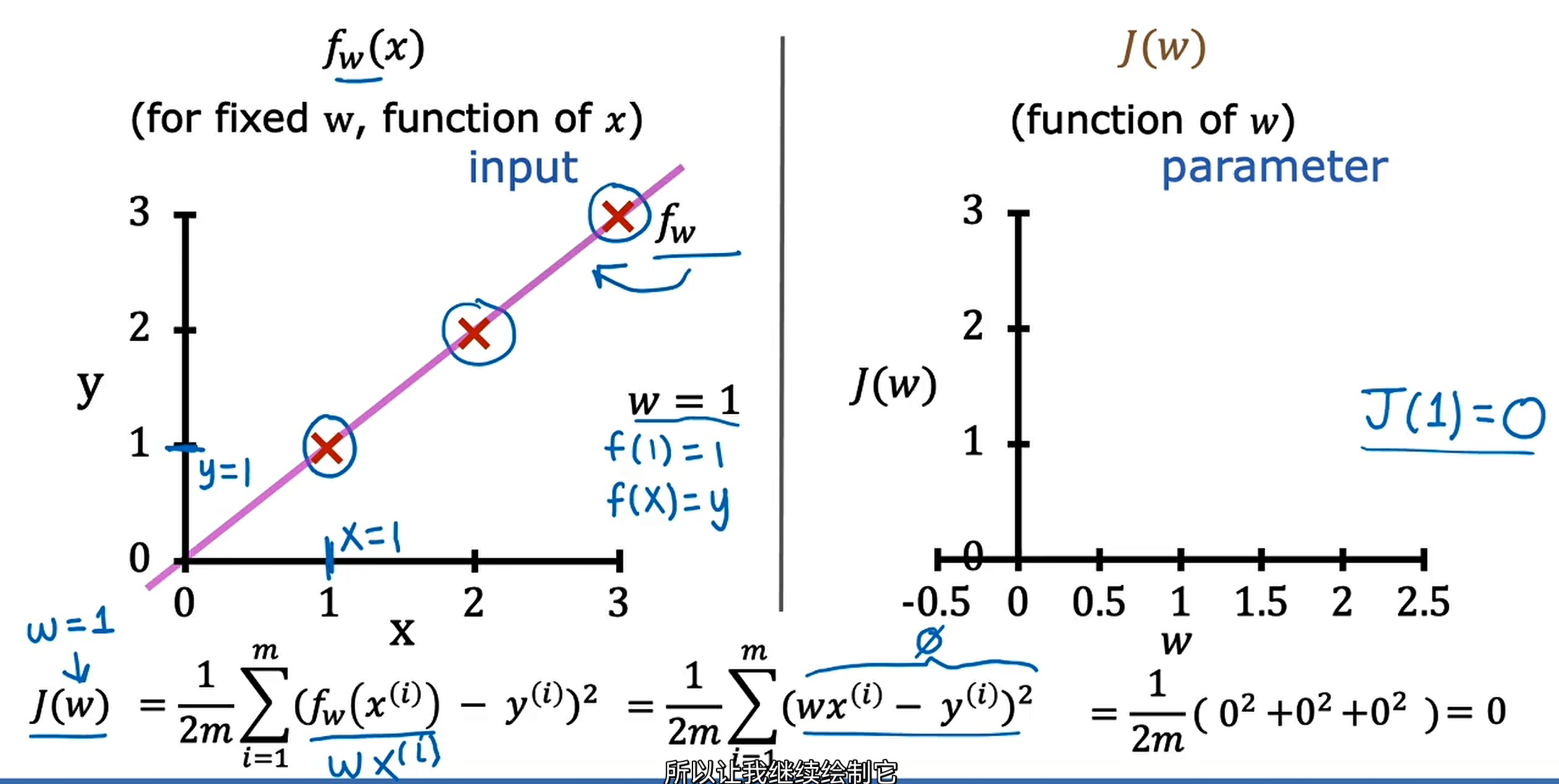
$f_{w}(x)$ (for fixed w, function of x) (here, x is input)
J(w) (function of w) (here , w is parameter)
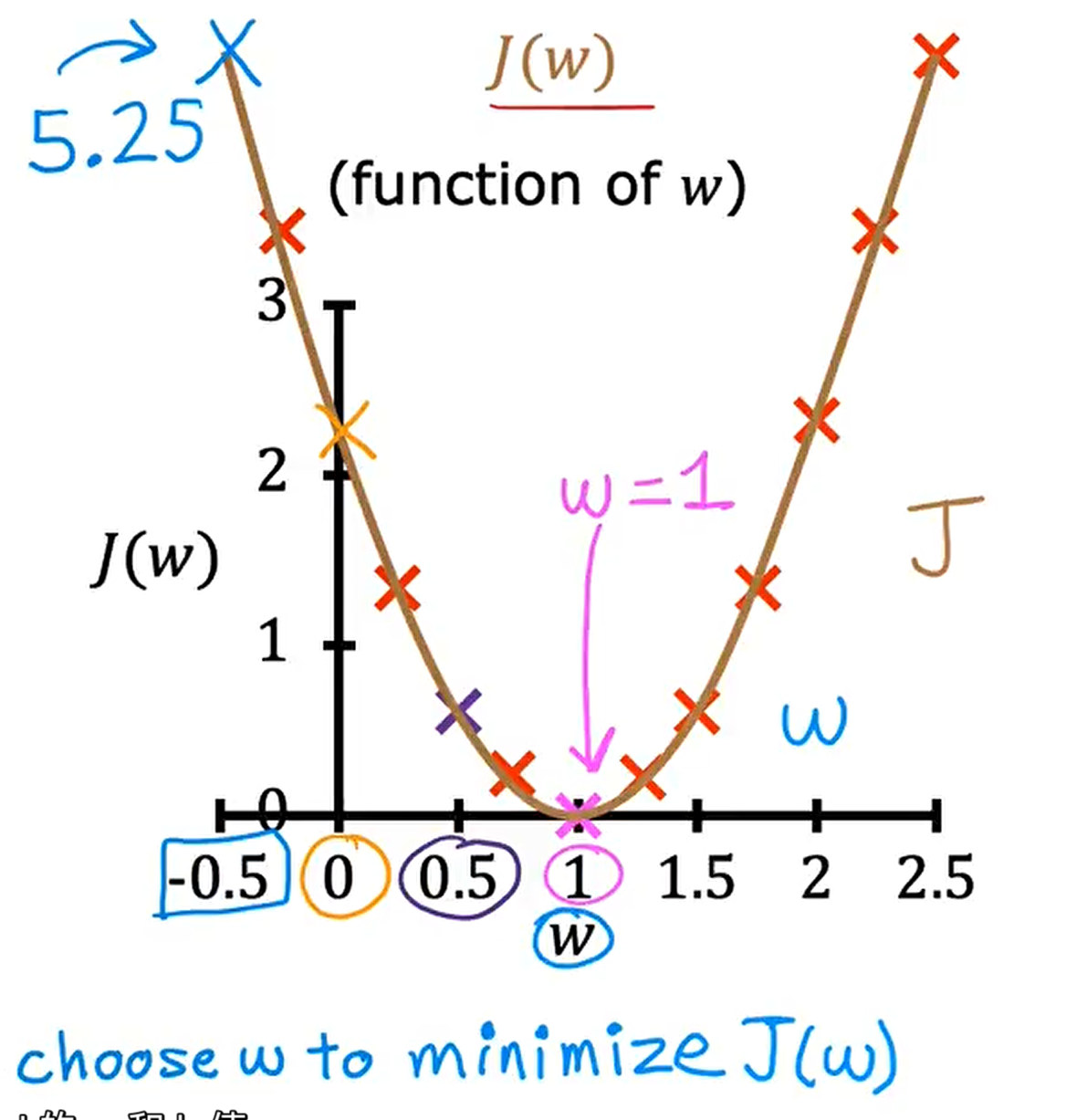
choose w to minimize J(w)
3D Visualizing
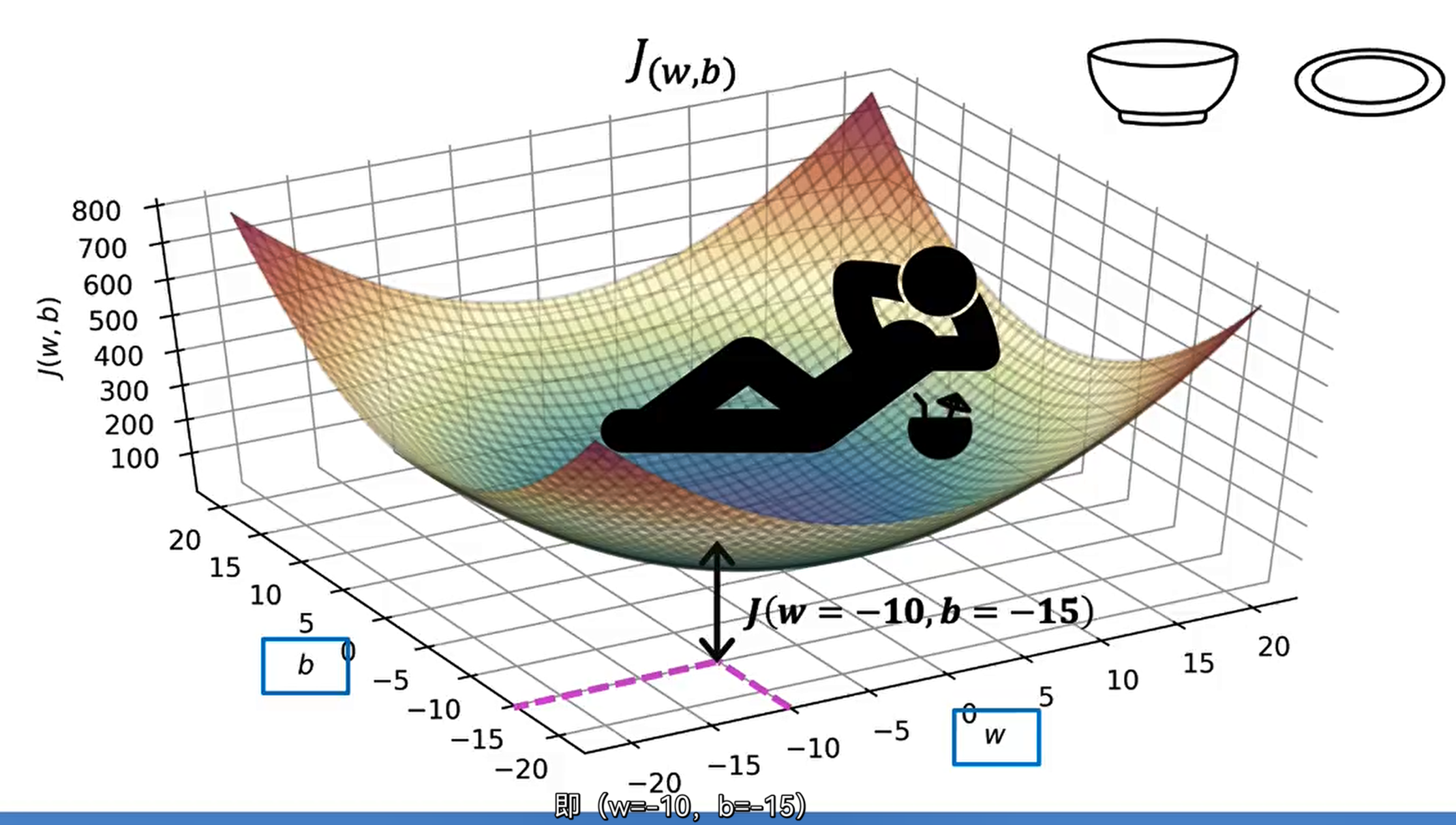
4st
==Gradient Descent(梯度下降)==
Have some function J(w,b)
want to $\mathop{min} \limits_{w,b} J(w,b)$
$\mathop{min} \limits_{w_{1},...,w_{n},b}J(w_{1},w_{2},...,w_{n},b)$
Outline:
Start with some w,b(is not important)(so set w=0,b=0)
Keep changing w,b to reduce J(w,b)
Until we settle at or near a minimum(may have >1 minimum)
Gradient descent algorithm
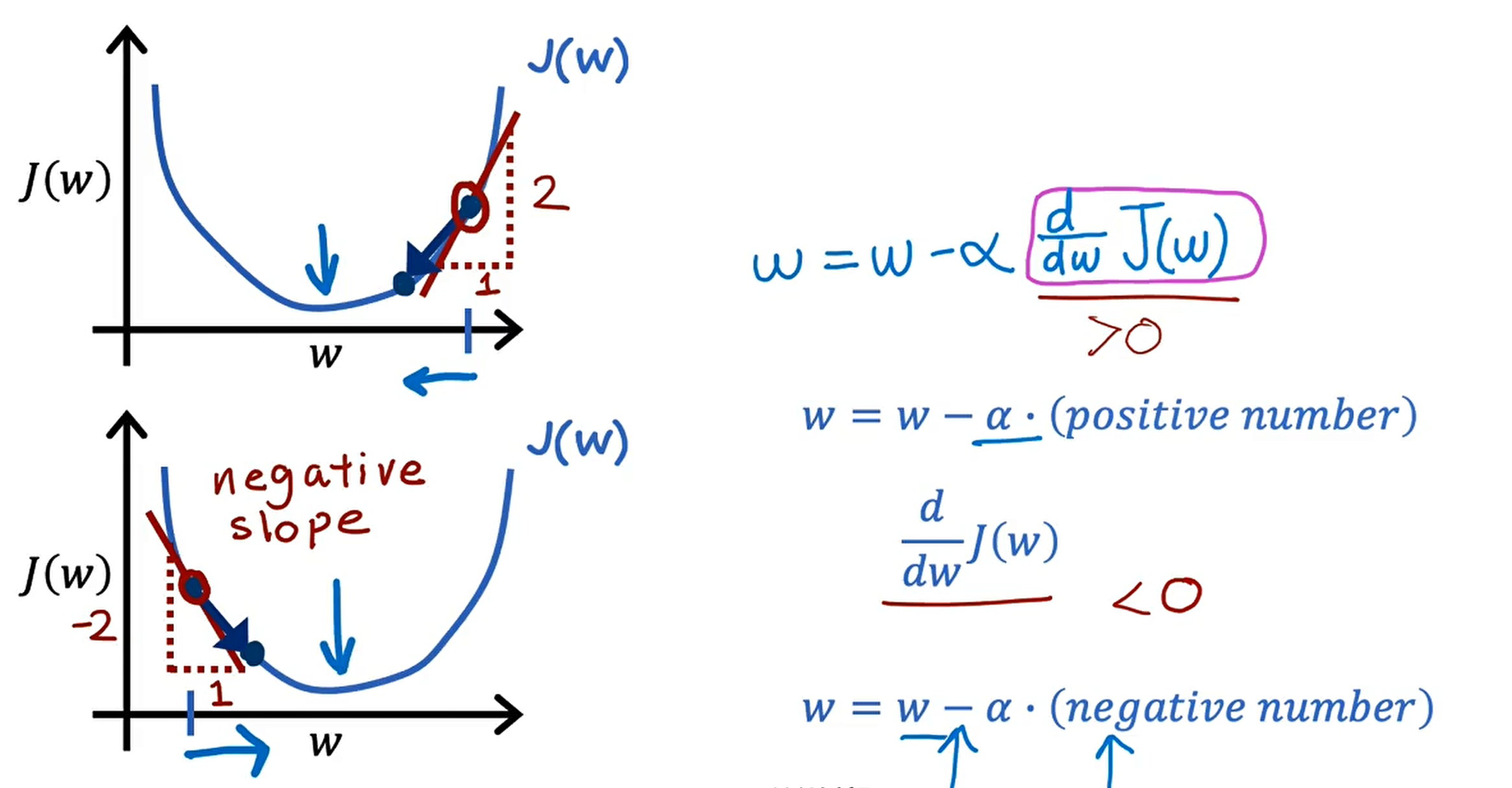
$w = w - \alpha \frac{\partial}{\partial w} J(w,b)$
$\alpha$ : Learning rate
$\frac{\partial}{\partial w} J(w,b)$ : Derivative(导数)
$b = b - \alpha \frac{\partial}{\partial b} J(w,b)$
Simultaneously update w and b
Correct : Simultaneous update
$tmp\_w = w - \alpha \frac{\partial}{\partial w} J(w,b)$
$tmp\_b = b - \alpha \frac{\partial}{\partial b} J(w,b)$
$w = tmp\_w$
$b = tmp\_b$
Order of attention
Gradient Descent Intuition (梯度下降的直观理解)
$w = w - \alpha \frac{\partial}{\partial w} J(w)$
学习率